My Journey with kernel: ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen - AKA When SATA fails under heavy load
How to reproduce
vzrestore from a .tar with both source and destination on the same raid1 device whilst there is a simultaneous 'lighter' write operation.
PS: If you end up here and have any more information about this I would love to hear from you.
Attempts to fix it
I wasn't clever enough to think of these myself, this is just a list of things that other folk with similar errors said worked for them.
- acpi=off noapic - didn't help, it still happened. (I didn't try libata.noacpi=1)
- Disable write cache /sbin/hdparm -W0 /dev/sdX - helped ?maybe?, but still not perfect.
- With everything on the root volume i thought perhaps the snapshot was an issue, there seemed to be some notion that snapshotting the system volume was the issue. I repartitioned and mounted the VPS images on a seperate LV. Situation improved, but still not perfect.
- Turn off NCQ echo 1 > /sys/block/sdX/device/queue_depth still no luck. (I didn't try libata.force=noncq)
- libata.force=1.5Gbps seems to have worked, but I don't really know why. The more I look the less consensus there seems to be, but for me this worked - I'm now 2 days in, 2 raid rebuilds and 12 LVM snapshotted backups (during the [forced] rebuilds) - not one hint of a problem.
- I've noticed this thread http://www.msfn.org/board/topic/128092-seagate-barracuda-720011-troubles/ that could be a clue, but I don't think my drives are affected. I have just replaced one of them (about the same time as forcing 1.5Gbps) with an Hitachi but the other is still in there.
- Also added libata.noncq and libata.noacpi=1
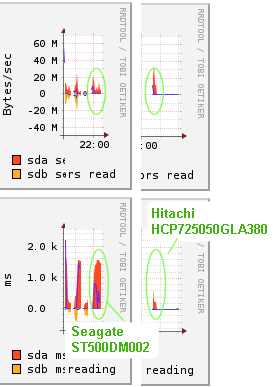
- OK, It's (d) NONE OF THE ABOVE. All they were doing were avoiding the load that caused the first error. A certain operation yields this graph. The Seagates clearly keep the CPU's waiting for over 2 seconds for IO to return where as the Hitachi doesn't. This results in a "task blocked for more than 120 seconds" message and invariably the system hangs up for a few seconds.
- Replacing the Seagate drives looks to be the real solution. They seem to respond badly to heavy random IO, but were faster for vaugely sequential IO - still the failure mode was horrendous and I believe due to over optimisation within the firmware. After replacing these with either Hitachi or Western Digital drives the restore completes in 5 minutes with no hangs or other messages in /var/log/syslog.
The Error (this the first one)
Jan 13 14:22:15 cis01 kernel: ata1.00: exception Emask 0x0 SAct 0x0 SErr 0x0 action 0x6 frozen
Jan 13 14:22:15 cis01 kernel: ata1.00: failed command: FLUSH CACHE EXT
Jan 13 14:22:15 cis01 kernel: ata1.00: cmd ea/00:00:00:00:00/00:00:00:00:00/a0 tag 0
Jan 13 14:22:15 cis01 kernel: res 40/00:08:ff:71:fe/00:00:17:00:00/40 Emask 0x4 (timeout)
Jan 13 14:22:15 cis01 kernel: ata1.00: status: { DRDY }
Jan 13 14:22:15 cis01 kernel: ata1: hard resetting link
Jan 13 14:22:21 cis01 kernel: ata1: link is slow to respond, please be patient (ready=0)
Jan 13 14:22:25 cis01 kernel: ata1: COMRESET failed (errno=-16)
Jan 13 14:22:25 cis01 kernel: ata1: hard resetting link
Jan 13 14:22:31 cis01 kernel: ata1: link is slow to respond, please be patient (ready=0)
Jan 13 14:22:36 cis01 kernel: ata1: COMRESET failed (errno=-16)
Jan 13 14:22:36 cis01 kernel: ata1: hard resetting link
Jan 13 14:22:41 cis01 kernel: ata1: link is slow to respond, please be patient (ready=0)
Jan 13 14:23:11 cis01 kernel: ata1: COMRESET failed (errno=-16)
Jan 13 14:23:11 cis01 kernel: ata1: limiting SATA link speed to 1.5 Gbps
Jan 13 14:23:11 cis01 kernel: ata1: hard resetting link
Jan 13 14:23:16 cis01 kernel: ata1: COMRESET failed (errno=-16)
Jan 13 14:23:16 cis01 kernel: ata1: reset failed, giving up
Jan 13 14:23:16 cis01 kernel: ata1.00: disabled
Jan 13 14:23:16 cis01 kernel: ata1: EH complete
Jan 13 14:23:16 cis01 kernel: sd 0:0:0:0: [sda] Unhandled error code
Jan 13 14:23:16 cis01 kernel: sd 0:0:0:0: [sda] Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Jan 13 14:23:16 cis01 kernel: sd 0:0:0:0: [sda] CDB: Write(10): 2a 00 17 a9 ed 5f 00 00 08 00
Jan 13 14:23:16 cis01 kernel: end_request: I/O error, dev sda, sector 397012319
Jan 13 14:23:16 cis01 kernel: md/raid1:md0: Disk failure on sda1, disabling device.
Jan 13 14:23:16 cis01 kernel: md/raid1:md0: Operation continuing on 1 devices.
Jan 13 14:23:16 cis01 kernel: sd 0:0:0:0: [sda] Unhandled error code
Jan 13 14:23:16 cis01 kernel: sd 0:0:0:0: [sda] Result: hostbyte=DID_BAD_TARGET driverbyte=DRIVER_OK
Jan 13 14:23:16 cis01 kernel: sd 0:0:0:0: [sda] CDB: Read(10): 28 00 01 3d 68 f7 00 00 08 00
Jan 13 14:23:16 cis01 kernel: end_request: I/O error, dev sda, sector 20801783
Jan 13 14:23:16 cis01 kernel: md/raid1:md0: sda1: rescheduling sector 20801720
The Error (the second one, after the first was suppresed)
kjournald could be anything - this was just one example.
Jan 14 15:18:21 cis01 kernel: INFO: task kjournald:2285 blocked for more than 120 seconds.
Jan 14 15:18:21 cis01 kernel: "echo 0 > /proc/sys/kernel/hung_task_timeout_secs" disables this message.
Jan 14 15:18:21 cis01 kernel: kjournald D ffff88043bca8ce0 0 2285 2 0 0x00000000
Jan 14 15:18:21 cis01 kernel: ffff88043d743c30 0000000000000046 ffff88045622d440 ffff88043c7fcc00
Jan 14 15:18:21 cis01 kernel: ffff88043d743bb0 000000000000f788 ffff88043d743fd8 ffff88043bca8ce0
Jan 14 15:18:21 cis01 kernel: ffff88043e6cb020 ffff88043bca92a8 ffff8801a0094000 ffff88043bca92a8
Jan 14 15:18:21 cis01 kernel: Call Trace:
Jan 14 15:18:21 cis01 kernel: [] ? dm_unplug_all+0x51/0x70
Jan 14 15:18:21 cis01 kernel: [] ? blk_unplug+0x56/0x60
Jan 14 15:18:21 cis01 kernel: [] ? dm_table_unplug_all+0x5d/0xd0
Jan 14 15:18:21 cis01 kernel: [] ? ktime_get_ts+0xb3/0xe0
Jan 14 15:18:21 cis01 kernel: [] ? read_tsc+0x16/0x40
Jan 14 15:18:21 cis01 kernel: [] ? ktime_get_ts+0xb3/0xe0
Jan 14 15:18:21 cis01 kernel: [] io_schedule+0xb2/0x120
Jan 14 15:18:21 cis01 kernel: [] sync_buffer+0x45/0x50
Jan 14 15:18:21 cis01 kernel: [] __wait_on_bit+0x62/0x90
Jan 14 15:18:21 cis01 kernel: [] ? sync_buffer+0x0/0x50
Jan 14 15:18:21 cis01 kernel: [] ? sync_buffer+0x0/0x50
Jan 14 15:18:21 cis01 kernel: [] out_of_line_wait_on_bit+0x79/0x90
Jan 14 15:18:21 cis01 kernel: [] ? wake_bit_function+0x0/0x50
Jan 14 15:18:21 cis01 kernel: [] __wait_on_buffer+0x26/0x30
Jan 14 15:18:21 cis01 kernel: [] journal_commit_transaction+0xa4f/0x1280 [jbd]
Jan 14 15:18:21 cis01 kernel: [] ? lock_timer_base+0x3b/0x70
Jan 14 15:18:21 cis01 kernel: [] ? try_to_del_timer_sync+0xac/0xe0
Jan 14 15:18:21 cis01 kernel: [] kjournald+0xed/0x240 [jbd]
Jan 14 15:18:21 cis01 kernel: [] ? autoremove_wake_function+0x0/0x40
Jan 14 15:18:21 cis01 kernel: [] ? kjournald+0x0/0x240 [jbd]
Jan 14 15:18:21 cis01 kernel: [] kthread+0x96/0xb0
Jan 14 15:18:21 cis01 kernel: [] child_rip+0xa/0x20
Jan 14 15:18:21 cis01 kernel: [] ? kthread+0x0/0xb0
Jan 14 15:18:21 cis01 kernel: [] ? child_rip+0x0/0x20
The system:
- 2 X 500GB SATA drives
- THESE ARE THE "FAULTY" DRIVES THAT FAIL UNDER HEAVY RANDOM IO. Needless to say they are no longer in the system.
Device Model: (Seagate) ST500DM002-1BD142
Firmware Version: KC44
- THESE ARE THE "FAULTY" DRIVES THAT FAIL UNDER HEAVY RANDOM IO. Needless to say they are no longer in the system.
- Supermicro X8DTL-iF Motherboard
- Dual Quad core Intel(R) Xeon(R) CPU E5606 @ 2.13GHz
- 16GB (8x2) RAM per CPU (so 32GB)
- Debian 2.6.32-6-pve (Proxmox) x86_64
- Software raid1 (mdadm) with LVM